
AI, LLM, Agents, etc
quarterly AI post
I have a theory about creation with AI.
(wait! please come back)
My gut says this can’t be original, but I haven’t seen it exactly expressed anywhere.
- The best art (and I’ll extend this to products in general) reflects the taste and discernment of just one person, or at least very few people.
- LLM’s represent the antithesis of that, the voice of the masses, and perhaps worse: the voice of the masses digested by a deflavorizing machine.
- The skill in creating with LLM’s is then to remain in charge, to make sure YOUR taste and discernment are dominant. If this effort gets in the way of creating, then the LLM is harmful to your endeavor.
- Code has the opposite dynamic! You generally want the most generic, boring, un-creative implementation of a thing, unless you’re trying to break new ground in computer science. The voice of the masses is an asset.
I think one way to navigate #3 (at least for digital projects) is tool building, using AI not to necessarily make the thing, but make to make peripheral tools that improve your life or make creating more productive or pleasant. For SpinDoc, I don’t plan on using AI for graphics, game design, level design, etc– but the level editor is a place where “taste and discernment” doesn’t matter so much (at least not yet), and letting the LLM do most of the work on that has been helpful to me.
Crossing the streams
At work, I’ve been diving into AI/LLM stuff, and I’m still pretty much always using coding assistants when I work on DC Tech Events. I hadn’t really attempted to bring that into game development, though. Last week, I decided to try it on my current roguelike project.
This game began life as part of a 10-day game jam, and I was beginning to regret some of the architectural compromises I made under the time pressure. In particular, the lines of responsibility were pretty murky between the class that generated maps, and the one that displayed the map and tracked positions. I gave Github Copilot some direction on what functionality belonged where, and it did a credible job cleaning things up, which made it easier for me to move on. Neat.
This led to some excitement and further experimentation, which resulted in two MCP servers, which allow a coding assistant more visibility and control of a a running Godot project. This one runs outside of Godot, and connects to the debugging port and language server, while the other is a Godot Plugin, and provides an HTTP server that allows for an agent to manipulate the node tree, and even send input. It’s cool when it’s all working.
As a “big swing” experiment, I created an empty project with a single spritesheet, and asked copilot to make a match 3 game. The game itself turned out OK, but across many attempts it completely failed to identify which parts of the sheet should be used as game pieces. Score one for humanity!
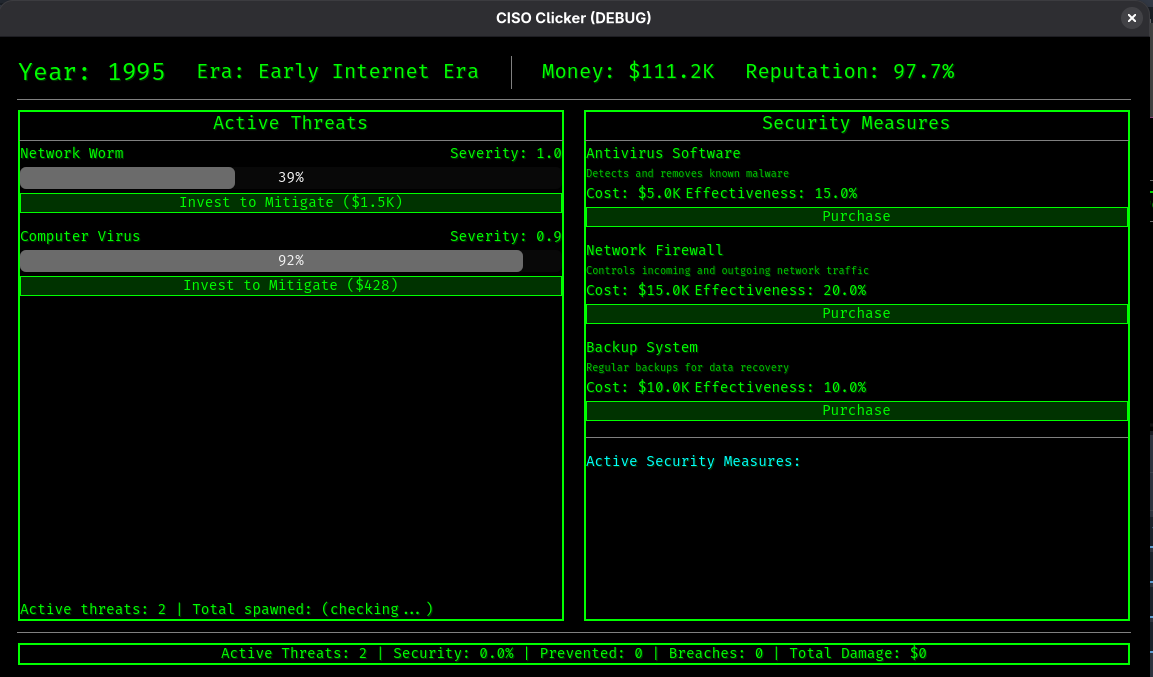
I’ve started a lot of projects and finish basically none of them– I think the promising thing for me is that I can use coding agents to get past the annoying/tedious tasks that cause me to lose interest and move on, and finish more games. For example, at one point I started “CISO Clicker”, meant to be an idle/clicker game that hopefully imparts some wisdom about the asymmetric nature of cybersecurity. I never really got past generating some company names.
With a few prompts, I’ve got a start on exactly the sort of simulation I’ve been thinking about:
soaking in it
I know, a few weeks ago I wrote “the internet doesn’t need more words about AI”.
Since then, I started working at a company that considers AI as part of it’s toolkit for helping customers, contributed some code to an internal project that uses the Google Gemini API, and my first client project?
Helping write LLM policy.
¯\_(ツ)_/¯
I’ve tried and failed a couple of times to write some sort of position statement in this space, that would capture a mix of hope and fear, while giving myself permission to keep learning and experimenting. I could probably have ChatGPT write it, but I’m not so far gone as to subject readers to machine-written prose.
I am giving myself that permission to learn and experiment, though. Program or Be Programmed seems newly relevant, and I think the closing words of LLMs Are Weird Computers captures the moment pretty well:
But I will say that if you don’t want to be caught with your pants down when your workplace does expect you to do more and different things with this technology, there’s no better time than now to start learning how to use it.
Musings of an LLM Using Man
I know, the internet doesn’t need more words about AI, but not addressing my own usage here feels like an omission.
A good deal of the DC Tech Events code was written with Amazon Q. A few things led to this:
- Being on the job market, I felt like I needed get a handle on this stuff, to at least have opinions formed by experience and not just what I read on the internet.
- I managed to get my hands on $50 of AWS credit that could only be spent on Q.
So, I decided that DC Tech Events would be an experiment in working with an LLM coding assistant. I naturally tend to be a bit of an architecture astronaut. You could say Q exacerbated that, or at least didn’t temper that tendency at all. From another angle, it took me to the logical conclusion of my sketchiest ideas faster than I would have otherwise. To abuse the “astronaut” metaphor: Q got me to the moon (and the realization that life on the moon isn’t that pleasant) much sooner than I would have without it.
I had a CDK project deploying a defensible cloud architecture for the site, using S3, Cloudfront, Lambda, API Gateway, Cognito, and DynamoDB. The first “maybe this sucks” moment came when I started working on tweaking the HTML and CSS, and I didn’t have a good way to preview changes without doing the whole cdk deploy routine, which could take a couple of minutes.
That led to a container-centric refactor, that was able to run locally using docker compose. This is when I decided to share an early screenshot. It worked, but the complexity was starting to make me feel nauseous.
This prompt was my hail mary:
Reimagine this whole project as a static site generator. There is a directory called _groups, with a yaml file describing each group. There is a directory called _single_events for events that don’t come from groups(also yaml). All “suggestions” and the review process will all happen via Github pull requests, so there is no need to provide UI or API’s enabling that. There is no longer a need for API’s or login or databases. Restructure the project to accomplish this as simply as possible.
The aggregator should work in two phases: one fetches ical files, and updates a local copy of the file only if it has updated (and supports conditional HTTP get via etag or last modified date). The other converts downloaded iCals and single event YAML into new YAML files:
- upcoming.yaml : the remainder of the current month, and all events for the following month
- per-month files (like july.yaml)
The flask app should be reconfigured to pull from these YAML files instead of dynamoDB.
Remove the current GithHub actions. Instead, when a change is made to
main, the aggregator should run, freeze.py should run, and the built site should be deployed via github page
I don’t recall whether it worked on the first try, and it certainly wasn’t the end of the road (I eventually abandoned the per-month organization, for example), but it did the thing. I was impressed enough to save that prompt because it felt like a noteworthy moment.
I’d liken the whole experience to: banging software into shape by criticizing it. I like criticizing stuff! (I came into blogging during the new media douchebag era, after all). In the future, I think I prefer working this way, over not.
If I personally continue using this (and similar tech), am I contributing to making the world worse? The energy and environmental cost might be overstated, but it isn’t nothing. Is it akin to the other compromises I might make in a day, like driving my gasoline-powered car, grilling over charcoal, or zoning out in the shower? Much worse? Much less? I don’t know yet.
That isn’t the only lens where things look bleak, either: it’s the same tools and infrastructure that make the whiz-bang coding assistants work that lets search engines spit out fact-shaped, information-like blurbs that are only correct by coincidence. It’s shitty that with the right prompts, you can replicate an artists work, or apply their style to new subject matter, especially if that artist is still alive and working. I wonder if content generated by models trained on other model-generated work will be the grey goo fate of the web.
The title of this post was meant to be an X-Files reference, but I wonder if cigarettes are in fact an apt metaphor: bad for you and the people around you, enjoyable (for some), and hard to quit.